A fun experiment turned into a surprisingly valuable lesson for us. As part of building the hybrid workflow demo, we were working on understanding loan application documents—particularly images of them.
My conversations with Aravind and Vibhor revolved around document extraction, accuracy, and the user experience. Here are the key steps we focused on:
- Accuracy of extraction – How well can AI pull information from the document?
- Understanding the extracted data – What meaning does the AI infer?
- Decision-making – How do we use AI to take decisions?
- Presentation of the data – How do we show the extraction, inference and decision in a way that makes sense to the user?
- Human interaction – How does the user engage with the information effectively?
Vibhor had written here about the importance of good human interaction in one of his previous posts.
The Grocery Bill Experiment
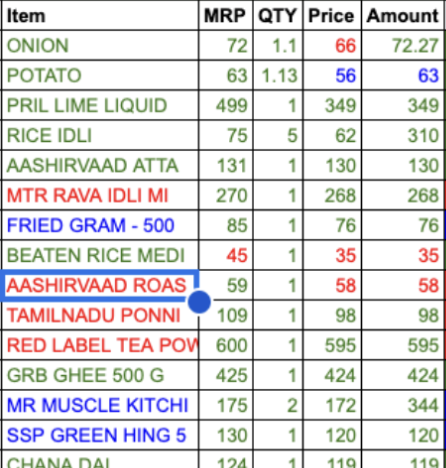
One day, Aravind decided to toss his latest grocery bill—41 rows and 5 columns of data, or 205 items—at a few large language models (LLMs). The idea was simple: Can these LLMs accurately extract and understand this data?

Prompt: “Convert this itemized bill to a csv file with 5 columns: item, MRP, QTY, Price Amount”
He tested with three models:
- Claude Sonnet 3.5 – 94.1% accuracy
- GPT-4 – 85% accuracy
- Gemini 1.5 Flash – 93.7% accuracy
Interestingly, repeated runs with the same LLM and the same prompt gave different results (e.g., ChatGPT gave 78% accuracy once and 85% the next time).
Are all LLM mistakes hallucinations?
When Aravind was testing LLM outputs, he noticed that not all errors were created equal. Here’s what he found:
- An honest mistake: 66 was read as 65.
- Smart approximation (textual): Mr. Muscle Kitch became Mr. Muscle Kitchen
- Smart approximation (mathematical): An LLM got the price right (170) but inferred a quantity of 2 instead of 1, and calculated a total of 340.
- Confabulation: A non-existent item, Tamilnadu Ponni, appeared in the bill.
- Complete hallucination: 172 was read as 335.
Throwing all these errors into the "hallucination" bucket doesn’t really help. Each type of mistake has its own quirks, and fixing them may require different approaches.
Why does this matter? If we treat every error the same, we’ll miss opportunities to improve the accuracy of LLMs. Understanding the nature of each mistake lets us apply more specific corrections and ultimately get better results.
Combining Results for Better Accuracy
Aravind didn’t stop there. He applied a "better of three" algorithm:
- If all three LLMs agreed, the result was taken with 100% confidence.
- If two out of three agreed, the result was taken with 67% confidence.
- If all three gave different results, he went with Claude's result, but with only 33% confidence.
This approach boosted accuracy to 99.5%—only one mistake out of 205 items. This method might not work for all document types. Different scenarios and types of documents require testing with other LLMs and combining their results using different algorithms.
This is an example of a vote-based ensemble.
Getting Technical – What Is an Ensemble?
Ensembling isn’t a new trick. It’s simply a method where multiple models—or even different versions of the same model—work together to improve results. By combining outputs from various models, we can boost accuracy and reliability, instead of relying on a single model’s prediction.
So, how does this work with LLMs? Here are a few ways to build an ensemble:
- Model Averaging: Here, multiple LLMs are trained independently. Their outputs—whether it’s probabilities or text—are averaged to create the final result. This approach helps reduce inconsistencies and makes the predictions more reliable.
- Voting-based: Different models generate responses, and the final answer is chosen based on a majority vote or other rules that combine their outputs. It’s like crowdsourcing the decision.
- Specialization-based Ensembles: Each model does what it’s best at. For example, one model handles factual accuracy, while another ensures smooth conversation flow. The results are then combined for a well-rounded answer.
- Sequential or Staged Ensembling: One model’s output is used as the input for another model. It’s a pipeline where each model builds on the last, refining the results step by step.
Ensembling can make LLMs perform better by reducing errors or biases. But, it also comes with a cost—more models running means higher computational power and resources.
Presentation Matters: Visualizing Confidence
Another key part of Aravind’s experiment was figuring out how to present the extracted data to users. He played around with the idea of using color codes to indicate the confidence level of each result:
- Green for 100% confidence,
- Blue for 67%, and
- Red for 33%.
This simple design would allow users to easily identify which values they might need to double-check. A clean UX is essential in making sure that users feel confident in the data they’re interacting with.
A More Complex Scenario
Now imagine a more complicated scenario—verifying income across bank statements, pay stubs, and tax returns. LLMs could extract and summarize this data, producing something like this:
“Mike Powell earned an average of $15,000 per month from May to July 2024, including a one-time bonus of $6,000 and rental income of $650 per month. Mike’s total income was $120,000 in 2022 and $126,000 in 2023. He has been with his current employer since April 2023, where his net pay increased by $1,900 per month.”
This was all deduced from pay stubs, 1099 forms, and bank statements. The challenge then becomes presenting these complex deductions in a way that feels intuitive to the user, especially when there are different confidence levels for each piece of information.
In the case of grocery bill, a color-coded confidence scale was a simple but effective way to show users what to trust and what to verify. What would a good UX look like to present the above statement with different confidence levels for different extractions and inferences?
The (U)X Factor
The key takeaway here is that while LLMs are great at extracting and interpreting data, the success of any AI tool depends on how easily users can interact with the results.
We think that designing a good UX, specific to the hybrid workflow use case will be one of the most important factors for GenAI adoption in business workflows.
Write to us if you have some interesting use cases for Hybrid workflows and would like to discuss those with us.